
Data Lake: an Opportunity or a Dream for Big Data?
“Data Lake†is a massive, easily accessible data repository for storing “big dataâ€. Unlike traditional data warehouses, which are optimized for data analysis by storing only some attributes and dropping data below the level aggregation, a data lake is designed to retain all attributes, especially when you do not yet know what the scope of data or its use. Currently, Hadoop is the most common technology to create a data lake. It is important to distinguish the difference between Hadoop and a data lake. A data lake is a concept, and Hadoop is a technology to implement the concept.

A data lake holds a vast amount of raw data in its native format until it is needed. While a hierarchical data warehouse stores data in files or folders, a data lake uses a flat architecture to store data. Each data element in a lake is assigned a unique identifier and tagged with a set of extended metadata tags. When a business question arises, the data lake can be queried for relevant data, and that smaller set of data can then be analyzed to help answer the question.
Data Lake Capabilities
- Capture and store raw data at scale for a low cost.
- Store many types of data in the same repository.
- Perform transformations on the data.
- Define the structure of the data at the time it is used.
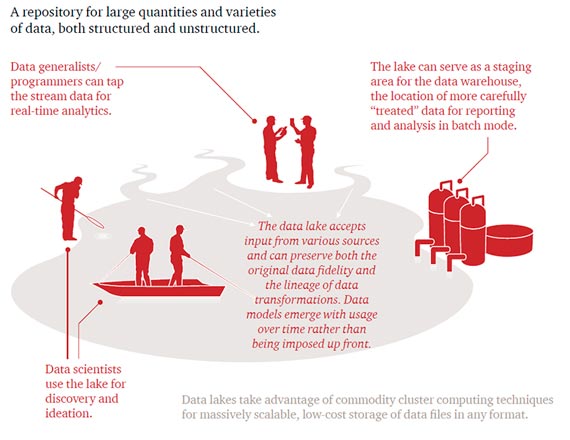
What is a data lake? / Credits: PWC
The term Data Lake is often associated with Hadoop-oriented object storage. In such a scenario, an organization’s data is first loaded into the Hadoop platform, and then business analytics and data mining tools are applied to the data where it resides on Hadoop’s cluster nodes of commodity computers.
Like big data, the term data lake is sometimes disparaged as being simply a marketing label for a product that supports Hadoop. However, the term is being accepted as a way to describe any large data pool in which the schema and data requirements are not defined until the data is queried.
The data lake promises to speed the delivery of information and insights to the business community without the hassles imposed by IT-centric data warehousing processes.
With a data lake, you simply dump all your data, both structured and unstructured, into the lake (i.e. Hadoop) and then let business people “distill†their own parochial views using whatever technology is best suited to the task (i.e. SQL or NoSQL, disk-based or in-memory databases, MPP or SMP.) And you create enterprise views by compiling and aggregating data from multiple local views.
Data Lake Advantages
- Data Lake gives business users immediate access to all.
- Data in the lake is not limited to relational or transactional.
- With a data lake, you never need to move the data.
- Data Lake empowers business users and liberating them from the bonds of IT domination.
- Data Lake speeds delivery by enabling business units to stand up applications quickly.
Data Lake Disadvantages
- Unknown area of Data Processing.
- Data governance.
- Dealing with Chaos.
- Privacy issues.
- Complexity of Legacy Data.
- Metadata Lifecycle Management.
- Desolate Data Islands.
- The Issue ofIntegration.
Now that data storage and technology is cheap, information is vast and newer database technologies don’t require an agreed upon schema up front, discovery analytics is finally possible. With data lakes, companies employ data scientists who are capable of making sense of untamed data as they trek through it. They can find correlations and insights within the data as they get to know it.
The Future
Some say the data lake is a dream, but we know of organizations that are making this approach a reality, the internal infrastructures developed at Google, Yahoo and Facebook provide their developers with the advantages and agility of the data lake dream. For each of these companies, the data lake created a value chain through which new types of business value emerged:
- Using data lakes for web data increased the speed and quality of web search.
- Using data lakes for clickstream data supported more effective methods of web advertising.
- Using data lakes for cross-channel analysis of customer interactions and behaviors provided a more complete view of the customer.
Regardless of where you are now, take some time to look to the future. We’re on a journey towards connecting enterprise data together. As business is increasingly becoming pure digital, access to data will become a critical priority, as will speed of development and deployment. The data lake is a dream that can match those demands.
This text is also published in Ahmed Banafa’s LinkedIn profile
Ahmed Banafa
Faculty | Author | Speaker | IoT Expert
References
http://www.gartner.com/newsroom/id/2809117?utm_content=buffer5fc11&utm_medium=social&utm_source=linkedin.com&utm_campaign=buffer
http://www.b-eye-network.com/blogs/eckerson/archives/2014/03/beware_of_the_a.php
http://siliconangle.com/blog/2014/08/07/gartner-drowns-the-concept-of-data-lakes-in-new-report/
http://www.ibmbigdatahub.com/blog/don%E2%80%99t-drown-big-data-lake
http://www.boozallen.com/media/file/FS_MakingTheCloudReign.pdf
http://www.wallstreetandtech.com/data-management/what-is-a-data-lake/d/d-id/1268851?
http://emcplus.typepad.com/.a/6a0168e71ada4c970c01a3fcc11630970b-800wi
http://hortonworks.com/wp-content/uploads/2014/05/TeradataHortonworks_Datalake_White-Paper_20140410.pdf
Source: OpenMind

